How we gained a 15x performance boost moving to an event-driven architecture for large-scale data processing
At Stacklok, we recently transitioned from a monolithic architecture to microservices for Trusty data ingestion and analysis, helping us scale our processing capability, reduce costs, and massively decrease the speed of fulfilling user requests.
Trusty is a free-to-use service from Stacklok that analyzes the packages in a number of public registries, including npm, pypi and crates, so that developers can make safer choices about the dependencies that they use. To analyze these packages requires an immense amount of data analysis. At Stacklok, we recently transitioned from a monolithic architecture to to an event-driven, microservices-based architecture for Trusty. This transition helped us scale our processing capability to 150 packages per minute, and massively decrease the speed of fulfilling user requests (from 20-30 seconds to a maximum of two seconds).
This transition was crucial to handling real-time updates for hundreds of packages per minute and ensuring a seamless user experience. In this blog post, we’ll share insights and lessons learned from scaling our backend operations and improving system responsiveness.
Challenges with a monolithic architecture
By default, Trusty will index and ingest data from the most popular packages in each ecosystem. When a user searches for a package that Trusty hasn’t yet indexed, Trusty can index that package on demand, ingest the data, and return the information to the user as fast as possible, nearly in real time.
Initially, Trusty operated on a monolithic architecture, methodically processing package data in sequence based on a state manager. This approach served us well at the outset, but as the platform expanded and the influx of data increased, we encountered challenges. With peaks reaching up to 100 packages per minute, the system struggled to process the load efficiently. Moreover, it lacked the flexibility to prioritize user-requested updates, leading to potential delays. Recognizing these limitations highlighted the need for a more adaptable and scalable system, prompting us to consider a shift towards microservices to enhance our service delivery and user experience.
The solution: Decoupling into microservices with an event-driven architecture
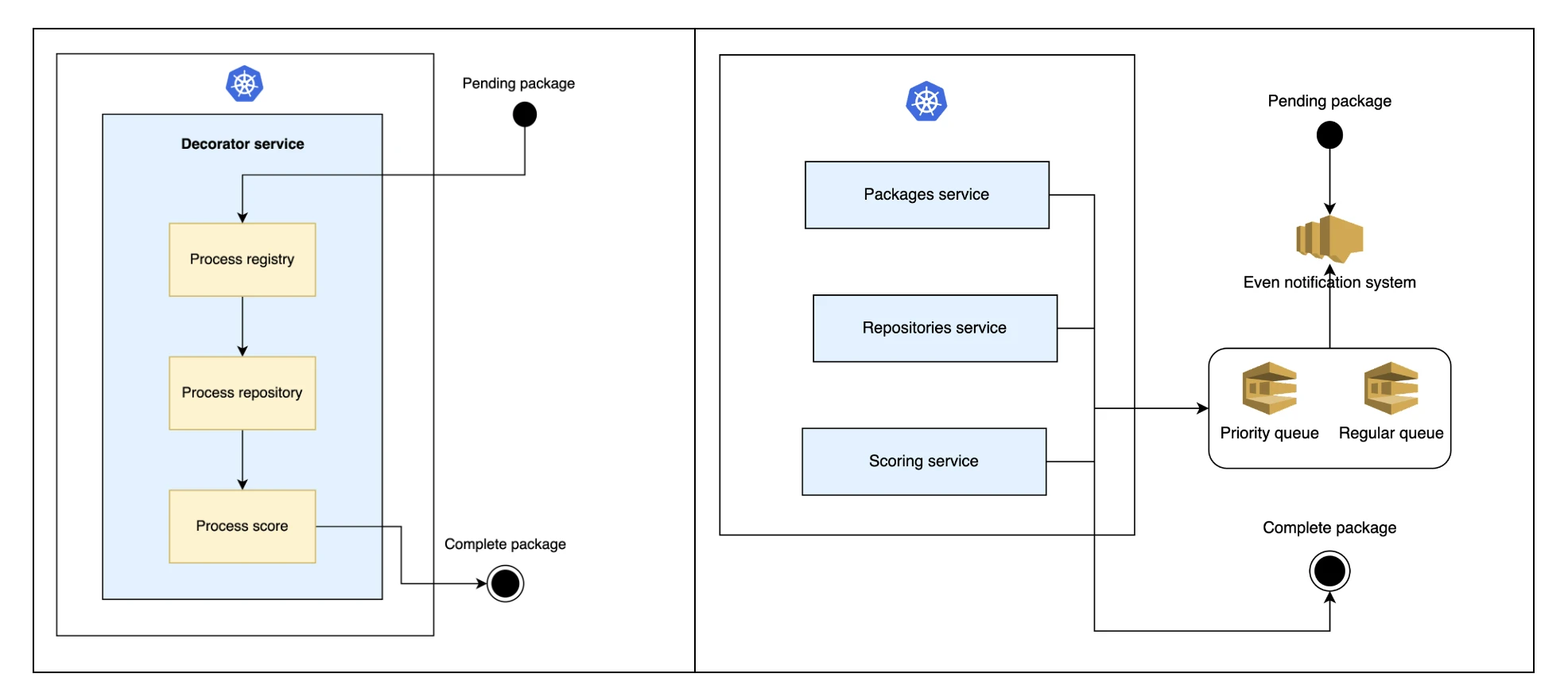
The initial step for decoupling a monolith into microservices is to identify the different and isolated parts of the monolith, and how they interact together. For Trusty, we dissected our monolithic architecture into three distinct microservices, each focusing on specific tasks: processing registry packages, extracting GitHub data, and scoring packages via machine learning.
Using a microservices architecture raised the need for effective communication between services. We moved to adopt an event-driven approach, where services react to and generate events, facilitating seamless interactions. This setup meant that when a package worker processes a task, it emits an event upon completion, triggering the next action in the workflow. Recognizing the importance of timely user-requested updates, we implemented two queues: a high-priority queue for urgent tasks and a regular queue for standard operations, ensuring that critical tasks are addressed promptly while maintaining overall system efficiency.
Trusty's new event-driven, microservices-based architecture
The main challenges we hit when decoupling the monolith was to define the communication workflow for this event-driven system. As we are running our service on AWS, a natural way of implementing this was using SNS and SQS, creating two different topics: a regular one for feeds and background tasks, and a priority one for user requests.
The process begins when the packages worker receives the initial event and initiates ingestion tasks within the package registries. Upon completion of these tasks, it publishes a new event to an SNS topic, which is then directed to the repositories queue. The repositories worker, monitoring this queue, undertakes similar tasks. Subsequently, the scoring worker processes the event, performing its designated tasks. Once completed, the package is marked as complete, signifying the end of the event sequence.
As events cannot be 100% reliable and some messages can be lost, there is also a regular reconciler process that runs hourly, detecting packages in an incorrect state, and performing the needed tasks to correct them.
Technical challenges of an SNS + SQS stack
The SNS + SQS stack is powerful, reliable, and cost effective. But it comes with some challenges. In our case, the main challenge was the lack of flexibility in terms of topic and queue creations, and how to subscribe queues to topics.
Before publishing any topic or consuming any queue, all resources need to be pre-created. As our system is dynamic, and as we need to add new topics and queues regularly, this became a challenge.
To solve this limitation, we created a procedure that creates or updates the related SNS resources each time that a new version of Trusty is released.
The structure of topics and queues to be created are based on a YAML file - to simplify integratio with development and testing. Our internal logic will detect the needed changes and will perform the right actions using AWS API:
This YAML indicates that those resources need to be created:
Topics: parse_registry, parse_repo, score_package
Queues: Priority and regular queues for packages, repositories and scores
Subscriptions: Each queue will be subscribed to the different topics using filters
In order to minimize the number of topics created, we used SNS message filtering. It means that we can send a message with different attributes to the topic, and queues will be subscribed to the topics with specific attributes, such as the priority.
The outcome: Faster and more efficient data processing
As mentioned, Trusty can ingest data from user requests or from package feeds. Feeds is an open source project that watches for new or updated packages in different registries, and publishes them via feed to different platforms.
In the case of Trusty, this information is published to an internal webhook endpoint, and is one of the main sources for adding new packages. At peak hours, Feeds can provide an amount of 100 packages per minute or more.
When a new package from Feeds is published, our system emits an event that is picked from packages-worker, and the whole flow starts. Here’s a demo of how this works:
In order to use package-feeds for our purposes, we needed to add some improvements, such as adding healthchecks to deploy the project into Kubernetes, or adding Java support. Being an open source project, we contributed back those enhancements upstream. We are also working on contributing an HTTP client capable of publishing the feeds to an HTTP webhook.
The enhancements implemented in our system have yielded significant benefits, notably in cost reduction and enhanced scalability. Transitioning from a monolith with periodic database queries to an on-demand notification system has led to a decrease in operational costs and improved efficiency. This shift has streamlined our processes, leading to a more effective system structure.
Our system's scalability has improved, with our processing capability now reaching up to 150 packages per minute, and user requests are fulfilled within a maximum of 2 seconds, a substantial improvement from the previous 20-30 seconds.
From this experience, we learned the importance of decomposing the system into microservices. This approach enabled us to view the system as a suite of components, each serving a distinct function. This division has allowed for more targeted development and management, underscoring the significance of specialized roles within the entire system. Adopting this framework has not only facilitated scalability and maintenance but also improved the system's robustness and flexibility in adapting to evolving requirements.